Technical Exam - Laravel Web Crawler
Question
Backend Challenge
Using PHP, build a web crawler to display information about a given website.
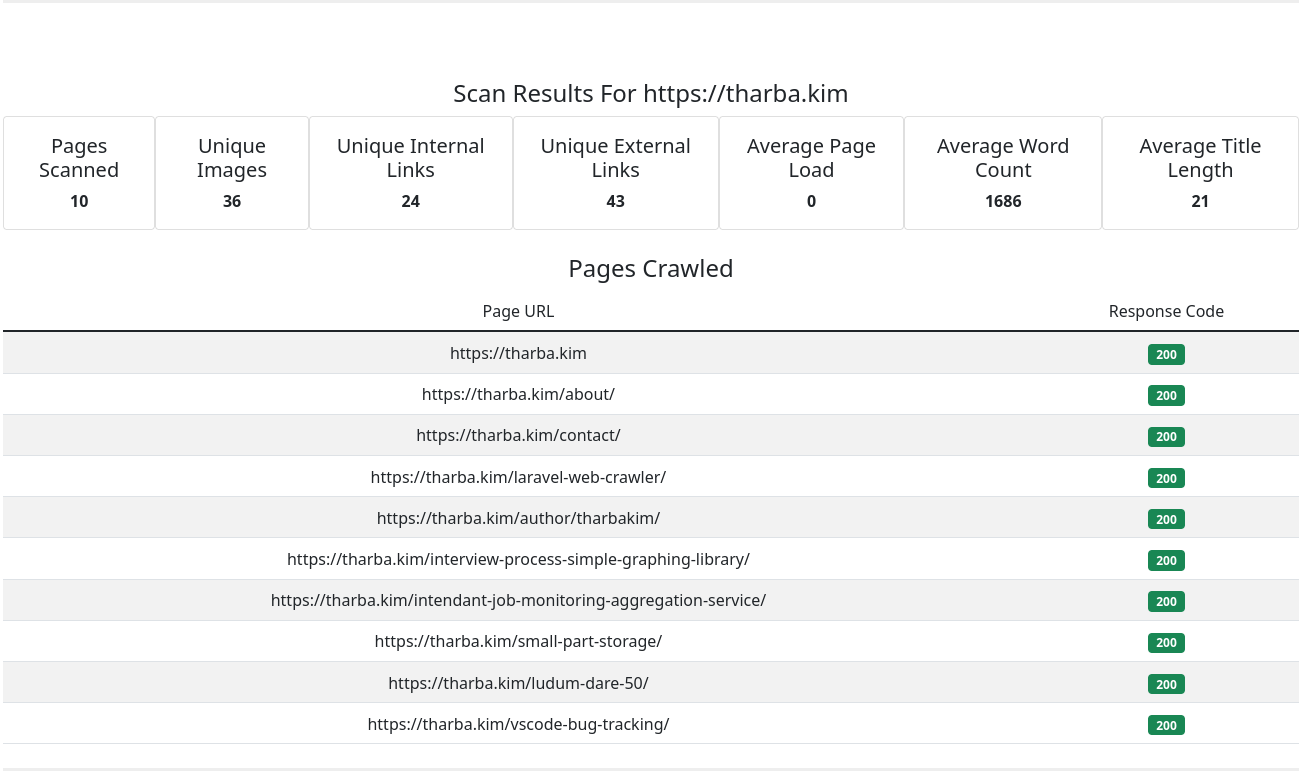
Crawl 4-6 pages of a website given a single entry point. Once the crawl is complete, display the following results:
* Number of pages crawled
* Number of a unique images
* Number of unique internal links
* Number of unique external links
* Average page load in seconds
* Average word count
* Average title length
* Also display a table that shows each page you crawled and the HTTP status code
Deploy to Heroku once finished.
Requirements
The app is built with PHP
The crawler is built for this challenge and not from a library
Bonus: Use of PHP 7 or 8 and its features
Bonus: Use of a framework such as Laravel or Phalcon
This question is a bit of a longer one, but most of the length comes from describing the required outputs in detail. Detailed explanation of the expectations is always welcome, so no complaints here.
Planning
It has been a long time since I have used the Laravel framework in a hobby setting, and the last time I used it professionally was never. Since at its core it is still a PHP project it will be deployed using a Docker container. Typically I would host this type of project myself, since deploying to Heroku is a part of the requirements I will be doing that. Fortunately Heroku supports deploying docker containers to its platform so it should be a straightforward process when I am done.
The bulk of this assignment is going to come down to parsing the contents of a webpage. I know Laravel offers a PSR-compliant wrapper around Guzzle, but in my prior experience with web crawling I have always reached for Python's Beautiful Soup library. Thinking about it briefly, the "content" of the webpage should all be contained in the <body> element, which means I should not need to worry about getting inline JavaScript or CSS caught up in my word count. If I can isolate the content of the body and then strip out all of the tags, I should get an accurate word count of the content. Similarly, it should be trivial to count the number of <a> or <img> tags in the body for the rest of the required statistics. I have used the DOMDocument class previously for similar parsing of HTML, so that will likely be what I turn to here. These thoughts of course are likely to change as I go.
There is no requirement to store any information long-term, so this truly is just a PHP solution, no database or file store required.
Since this is a "backend challenge", a basic interface for performing the search and displaying the results with the Bootstrap 5 library should suffice.
Nothing here seems to challenging or unknown, so it is time to dive in.
Laravel Setup
I know that Laravel Sail exists for using Laravel and Docker together, but every time I have seen it used was to simplify the configuration of tests and database/file store configuration. Since I am dealing with none of those, I am opting to use a "normal" docker container and docker tooling for the setup.
First off I need something to build and display in my docker container. Using my globally installed version of composer:
composer create-project laravel/laravel web
Generates a blank project in the web/ directory. This is enough to get started with the Docker configuration.
Since I am using PHP and I am going to end up making this a public repository, I want a "real" web server to front my application instead of relying on php-fpm. The PHP team provides a php:8-apache container that comes preconfigured for the Apache Web Server which I will be using, mostly because I am familiar with it. Being familiar with it, I already know that the rewrite apache module is not enabled by default. I plan to use said module (and Laravel uses it as well), so I will need to define my own container and enable it. Since there is no persistance required, I do not need to use a named volume or mount a directory from the host, I can set up the file structure within the Dockerfile.
FROM php:8-apache
RUN a2enmod rewrite
COPY ./web /var/www/html
COPY ./crawler/001-crawler.conf /etc/apache2/sites-available/001-crawler.conf
RUN chown -R www-data:www-data /var/www/html && a2ensite 001-crawler.conf && a2dissite 000-default.confAnd finally, a docker-compose.yml file to get us up and running:
version: "3"
services:
php-crawler:
build: "."
ports:
- "8086:80"With a docker-compose build and a docker-compose up -d, I now have a working Laravel instance to start developing in:
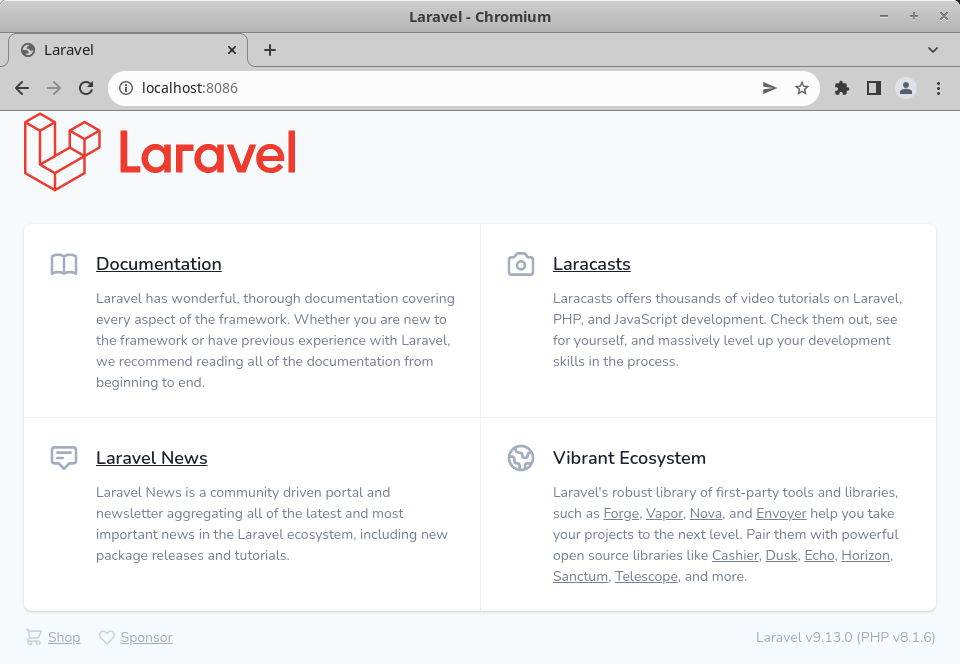
Search View
To kick things off, I need an interface to perform my search. Revisiting the requirements in the question:
Using PHP, build a web crawler to display information about a given website.
Crawl 4-6 pages of a website given a single entry point. Once the crawl is complete, display the following results
I am going to use 2 input values to perform the search - one to provide the initial URL to search from, and a second to choose how many additional pages to crawl before displaying the results. To prevent abuse or running through my Heroku allotted time, I will add in a limit on the backend later. I will also need to handle there not being enough unique URLs in the source of the page to reach the requested page number.
Laravel uses Blade Templates in their views, which I have worked with before: The LibreNMS project uses a blade template when generating email alerts.
Since the focus here is on backend development, I will not dive into the frontend content. If you are interested, it is available in the source at the end.
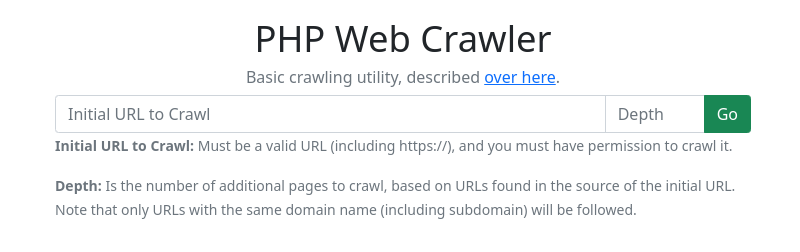
Search Route
Thinking about the way a user would use the application, it would not be uncommon for a user to want to perform multiple "crawls" in a single visit. Therefore the above input should also be available on the search result page. This means I can use a single route to handle all of my requests - a basic Nope, a better idea came to me as I started modifying the view to handle different request types. Although I am not storing any sort of data, it might be reasonable to expect that you would want to share your results with someone else, or check the results of a specific search on a regular basis. To make that a bit easier, I can move the parameters into the URL so that they can be shared and returned to. I still have to modify the view based on the parameters being present, but I gain a small "feature" in doing so.GET request for loading just the input field, and a POST request when I am submitting a URL for crawling.
This means I need to create my data model for my webpage so that I can pass it into the view when my request has the correct parameters. Since I am not storing the information in a database, Laravel's Eloquent is not the tool for the job. There are a few community-supported attempts at making an Eloquent-like interface for non-database models, but support for them is a bit of a wildcard. Thankfully Laravel is a library on top of PHP, so I can fall back to vanilla PHP to implement my data object.
Website Data Model
Revisiting the question, my data model needs to support the following values:
- Image URLs
- Internal Link URLs
- External Link URLs
- Page Load Time
- Word Count
- Title Length
- Page Title
- HTTP Response Code
- Page URL
Additionally, I want to know the following values to judge the performance of my parser:
- Parse Time
- Nodes Scanned
Of note, the "Image URLs" property has a couple interesting effects. Since the end goal is to display the number of unique images, I could check for uniqueness when adding images to my data model. However that would mean I no longer have the total number or the frequency of each image available in the future, although it would save us some memory during runtime. I am opting not to check for uniqueness here so that there is more data available.
Since this is a very simple data model, there is nothing too crazy about the requirements. A simple class with some basic get/set/add methods for each property will suffice:
<?php
namespace App\Models;
class Webpage
{
private array $images = array();
private array $internalUrls = array();
private array $externalUrls = array();
private string $loadTime;
private string $parseTime;
private int $nodesScanned = 0;
private int $wordCount = 0;
private string $pageTitle;
private int $httpResponse;
private string $pageUrl;
public function __construct($url)
{
$this->pageUrl = $url;
}
public function __toString(): string
{
return json_encode($this->getResult());
}
public function getResult(): array
{
return array(
"images" => count(array_unique($this->images)),
"internalUrls" => count(array_unique($this->internalUrls)),
"externalUrls" => count(array_unique($this->externalUrls)),
"loadTime" => $this->loadTime,
"parseTime" => $this->parseTime,
"nodesScanned" => $this->nodesScanned,
"wordCount" => $this->wordCount,
"pageTitle" => $this->pageTitle,
"httpResponse" => $this->httpResponse,
"pageUrl" => $this->pageUrl
);
}
public function addImage(string $url): void
{
array_push($this->images, $url);
}
public function getImages(): array
{
return $this->images;
}
public function addInternalUrl(string $url): void
{
array_push($this->internalUrls, $url);
}
public function getInternalUrls(): array
{
return $this->internalUrls;
}
public function addExternalUrl(string $url): void
{
array_push($this->externalUrls, $url);
}
public function getExternalUrls(): array
{
return $this->externalUrls;
}
public function getLoadTime(): string
{
return $this->loadTime;
}
public function setLoadTime(string $time): void
{
$this->loadTime = $time;
}
public function getParseTime(): string
{
return $this->parseTime;
}
public function setParseTime(string $time): void
{
$this->parseTime = $time;
}
public function addNodeScanned(): void
{
$this->nodesScanned++;
}
public function getNodesScanned(): int
{
return $this->nodesScanned;
}
public function addWordCount(int $words=1): void
{
$this->wordCount += $words;
}
public function getWordCount(): int
{
return $this->wordCount;
}
public function getPageTitle(): string
{
return $this->pageTitle;
}
public function setPageTitle(string $title): void
{
$this->pageTitle = $title;
}
public function getHttpResponse(): int
{
return $this->httpResponse;
}
public function setHttpResponse(int $code): void
{
$this->httpResponse = $code;
}
public function getPageUrl(): string
{
return $this->pageUrl;
}
}With my data model ready, I need to start crawling some webpages.
Web Crawler
Design
The web crawler will need to maintain an array of webpages that it has crawled using my Webpage data model - it will also be responsible for doing the web crawling.
Internally it needs to be able to make HTTP calls and parse the responses.
For the actual parsing of each webpage I am going to rely on the DOMDocument class built into PHP, which I have used before. I know that it ca not handle modern HTML tags for some reason, so I can not rely on its own error handling capabilities. However, this should be considerably faster than string comparisons against the raw text of the webpage, and much quicker (development time) than building out my own parse tree.
Before starting on parsing the responses, there are two decisions to be made:
* Number of Unique Images
What counts as a unique image? For starters, <img> tags are unique as long as their src value is different. What about <svg> nodes? They need to have a unique set of child elements to be considered unique, but that would also include icons like those provided by FontAwesome. Are those considered images? I would argue they are not, but what about more detailed SVG nodes? What about images that are loaded via CSS, with properties like backgroud-url or background-image? I could get a list of all the strings starting with http in the body and try to figure out which ones are images, but I would not know unless I also requested those URLs. I could potentially watch the network requests to see images as they are loaded but what about lazy-loading? When websites do not use the browser's lazy-loading capabilties but instead write their own, they often put the placeholder in the src attribute and use another attribute, such as data-src. Watching for netwok traffic could solve this, but would require a completely different setup utilizing something like Selenium or Playwright. Both of those are well above the scope of what I am trying to accomplish here, so I need to set some rules:
An "image" is one of the following:
- An
<img>node with asrcattribute, or adata-srcattribute (data-srctaking priority). - An
<svg>node with a unique set of child nodes
I am not detecting any node that does not match the first two requirements, but is affected by a background-image or background-url CSS property. This would require parsing the CSS present on each page, and checking each node against the parsed stylesheet for the presence of either property. Doable, but it seems outside the intended scope of the question.
If I set things up right, this means I should be able to fulfill all of my requirements in a single pass of the DOM tree. Time to start building a web crawler.
Implementation
Boilerplate
Since there is never a reason to need multiple parsers in a single PHP script I can avoid the overhead of needing to initialize a new object by creating my crawler as a series of static properties and methods. First I need somewhere to store my results as they come in:
static private array $webpages;And second, I need to make sure the URL I am about to try and request is a valid URL:
private static function isValidUrl($url)
{
return (filter_var($url, FILTER_VALIDATE_URL) !== false);
}In total, the setup code for doing the actual parsing looks like:
<?php
namespace App\Processor;
use Illuminate\Support\Facades\Http;
use App\Models\Webpage;
class WebCrawler
{
public static function crawl(string $seedUrl, int $depth): array
{
$webpages = array();
$seedPage = self::request($seedUrl);
array_push($webpages, $seedPage->getResult());
return $webpages;
}
private static function isValidUrl($url)
{
return (filter_var($url, FILTER_VALIDATE_URL) !== false);
}
private static function request(string|array $url): WEbpage
{
if (!self::isValidUrl($url)) {
throw new \App\Exceptions\InvalidUrlException("${url} is not a valid URL.");
}
if (is_array($url)) {
//Multiple URLs, request in concurrent mode?
} else {
$startTime = microtime(true);
$response = Http::get($url);
$elapsedTime = microtime(true) - $startTime;
$webpage = new Webpage($url);
$webpage->setLoadTime(strval($elapsedTime));
if ($response->ok() === true) {
$webpage->setHttpResponse($response->status());
if ($response->status() === 200) {
return self::parseWebsite($webpage, $response);
} else {
return $webpage;
}
} else {
return $webpage;
}
}
}
}The next big decision to make is how to traverse the DOM tree. Two major options here are to use the DOMDocument selector methods to pull out the node types that are needed for each calculation, but that involved taking multiple passes through the node tree looking for each node. Instead, I am going to opt for getting a list of all the possible nodes, and looping through them in one go. If there is a performance issue here due to some internal optimization in DOMDocument that will be my second attempt, but this should allow me to solve everything in almost one single pass.
First, lets test my current setup and make sure everything is working correctly. Since this is going to be an API call, the following addition to /web/routes/api.php should be enough:
Route::get('/crawl/{url}/{depth}', function ($url, $depth) {
return App\Processor\WebCrawler::crawl(urldecode($url), urldecode($depth));
});And to test it, lets parse an encoded url for google, https%3A%2F%2Fgoogle.ca:
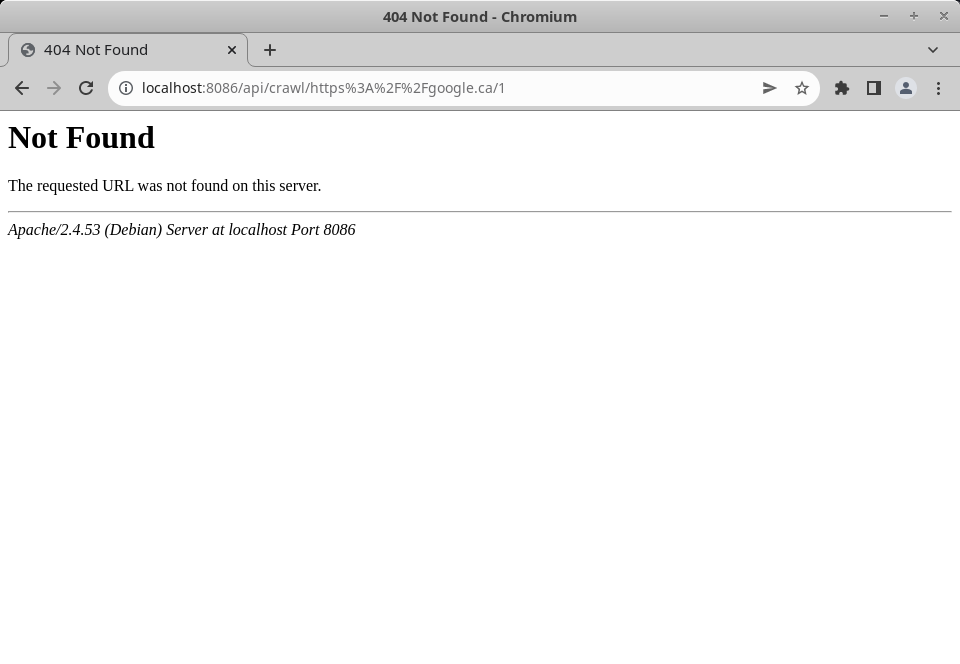
Nothing. Not even the Laravel exception handler. After a bit of research, it turns out Laravel's router does not allow you to use forward slashes in routes by default. Instead you have to explicitly allow it, even when the slashes are being passed as their encoded values. The router also seems to get confused when my slash-allowing parameter is not the last parameter for my route.
Route::get('/crawl/{depth}/{url}', function ($depth, $url) {
return App\Processor\WebCrawler::crawl(urldecode($url), urldecode($depth));
})->where('url', '.*');
Even more confusingly, the router falls apart altogether when you have two slashes together, as you do when specifying the protocol https:// as its encoded value. Pay attention to the URL in the two following screenshots:
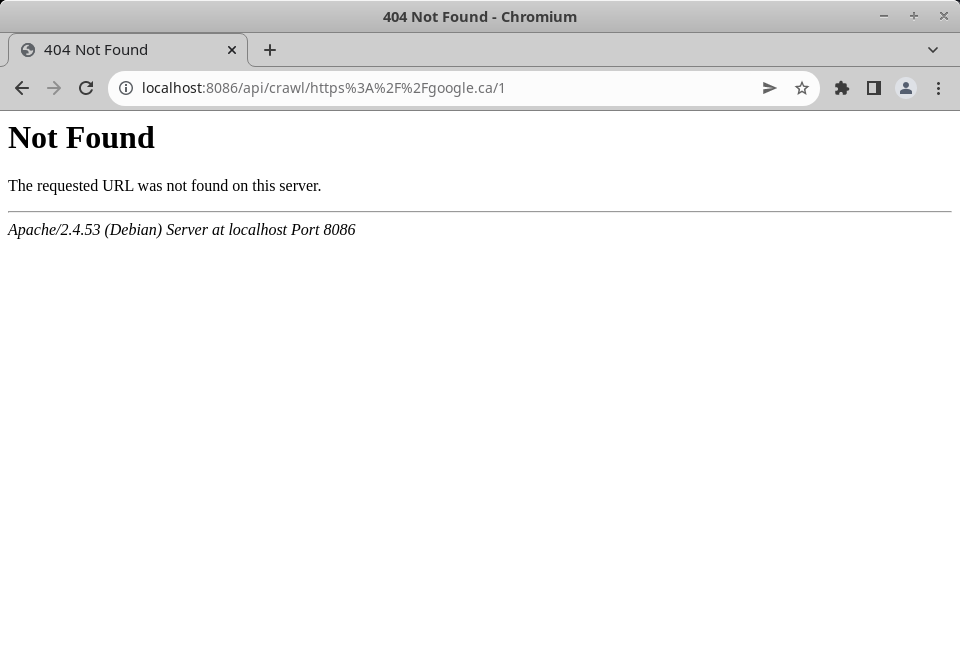
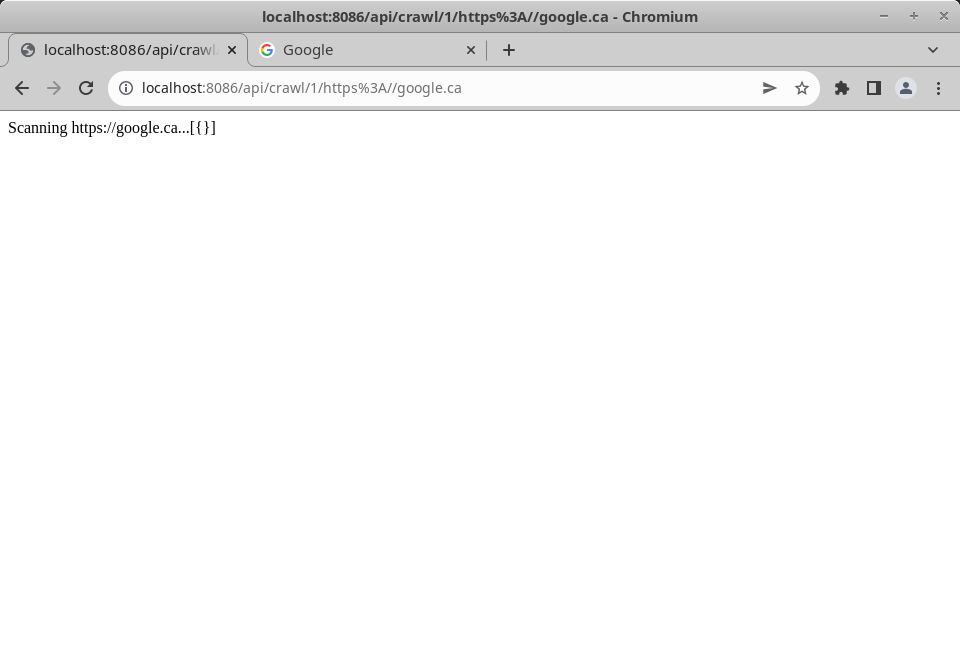
%2F%2F decoded into //.So to satisfy Laravel's router I need to pass the url parameter as an unencoded string. A bit odd, but that will no stop anything. Additionally, even more annoyingly Laravel seems to be stripping trailing / characters from every route entry, and when it does so it breaks the fix for handling routes with one or more / characters in an argument. Example:
With my existing route:
Route::get('/crawl/{depth}/{url}', function ($depth, $url) {
return App\Processor\WebCrawler::crawl(urldecode($url), urldecode($depth));
})->where('url', '.*');
/api/crawl/0/https://google.ca is a valid route.
/api/crawl/0/https://google.ca/ is intercepted by Laravel and modified before it gets to my router. Instead of my input, the request is mangled and processed as /api/crawl/0/https:/google.ca, which is no longer a valid URL. Firstly, the removal of the trailing slash is done in Laravel's public/.htaccess file, so lets remove it.
# Redirect Trailing Slashes If Not A Folder...
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} (.+)/$
RewriteRule ^ %1 [L,R=301]Now the page works correctly, and the mysterious removal of the // characters is gone.
Time to get to work writing a Web Crawler.
Implementation
As previously discussed, the first attempt will be to pull out all of the required information in a single scan of the nodes in the DOM tree.
A couple notes on working with DOMDocument objects:
- Trying to access node attributes is a frustrating exercise: Instead of assigning the values as
$attribute => $value, they are assigned as$iterator => array("name" => $name, "value" => $value). This search will end up in its own function as it will be used multiple times.
private static function checkForAttribute(\DOMNode $node, string $name): ?string
{
if ($node->hasAttributes()) {
foreach ($node->attributes as $index => $attribute) {
if ($attribute->name === $name) {
return $attribute->value;
}
}
}
return null;
}DOMNode objectSince I am attempting to do everything in one pass of the nodes, I will use a switch statement to check the node type on each node as I run through them.
libxml_use_internal_errors(true);
$startTime = microtime(true);
$dom = new \DOMDocument();
$dom->loadHTML($request->body());
$parsedUrl = parse_url($webpage->getPageUrl());
$nodes = $dom->getElementsByTagName('*');
foreach ($nodes as $node) {
$webpage->addNodeScanned();
switch ($node->nodeName) {nodesScanned property of my WebPage here, but by incrementing it on each node I gain an additional tool for debugging any issues.Lets get started:
Title
The page title is stored inside of the <title> tag, of which there can only be one tag per document.
case 'title':
$webpage->setPageTitle($node->textContent);
break;Images
As previously mentioned there are two tags to consider, <img> and <svg>. Additionally I am checking the data-src and src attributes of the <img> nodes to account for lazy-loading libraries:
case 'img':
$image = self::checkForAttribute($node, 'data-src');
if ($image !== null) {
$webpage->addImage($image);
break;
} else {
$image = self::checkForAttribute($node, 'src');
if ($image !== null) {
$webpage->addImage($image);
}
}
break;SVG elements can have all sorts of child nodes describing to a browser how to draw the image they represent, so there is no attribute I can look for here. What I can do though is get those "instructions" (child nodes) and save them instead.
case 'svg':
$webpage->addImage(htmlspecialchars($dom->saveHTML($node)));
break;Links
Getting the URLs in links will be simple enough, but I will also need to parse them to determine which URLs are internal vs external. I am also only going to detect a nodes with a src attribute, since I am not writing a parser for the page's JavaScript to look for click event handlers. Thankfully PHP has a built in function for parsing URLs into their components so most of the work is done already.
case 'a':
$url = trim(self::checkForAttribute($node, 'href'));
if ($url != "") {
if ($url[0] === "/") {
$url = "{$parsedUrl['scheme']}://{$parsedUrl['host']}$url";
$webpage->addInternalUrl($url);
} elseif ($url[0] === "#" || parse_url($url, PHP_URL_HOST) === parse_url($webpage->getPageUrl(), PHP_URL_HOST)) {
$webpage->addInternalUrl($url);
} else {
$webpage->addExternalUrl($url);
}
}Here anything links that start with a / (such as /about.html) are counted as an internal link after I prepend the scheme and host data back into the URL. This is important later. Additionally, anchor tags that refer to elements in the same page (such as #top) are counted as internal since they are technically "links". If a link does not contain either of those characters in the first position I compare the host of the URL to that of the original request. If those values match this is still an internal link, and if not it is external.
In some scenarios, such as when looking at /, /index, /index.html, /index.html it will be possible to have multiple "unique" links to the same page. I can address this later.
Notice that there is no break; statement at the end of the case for the <a> element. Since an <a> element will often have a text node associated with it (the text of the link that you click on) I need to make sure the next case also runs correctly.
Word Count
For my use case, a "word" is going to be any number of characters surrounded by whitespace. Therefore "4" and "&" are both valid words. I will remove some common punctuation (,, ., !, ?, / ) and consider that the word count. Alternative methods would be to remove numbers and "words" with 1 character length, or take a character count and divide by 4.
To start with, the DOMDocument class makes this a little but awkward to deal with. There is a simpler solution involving DOMXPath I could use, but that would require parsing the entire document a second time (and I hate the XPath query syntax, when will browsers start supporting newer version of it?). Instead, the only way for me to access these text nodes is by checking the children of each node as I iterate over the document. Thankfully text nodes have a different "type" assigned to them that I can check for:
default:
$children = $node->childNodes->length;
for ($i = 0; $i < $children; $i++) {
if ($node->childNodes->item($i)->nodeType === 3) {
$text = $node->childNodes->item($i)->textContent;
$text = str_replace(array(',', '.', '!', '?', ' / '), '', $text);
$text = preg_replace('/\s+/', ' ', $text);
$webpage->addWordCount(count(explode(' ', $text)));
}
}
break;I should now be able to test the crawler on a single page, so let me give it a go:

And that is a successful crawl.
Recursion
Next step is to handle the depth parameter I am passing to the web crawler. My take in this parameter is that it represents the additional pages that should be crawled. Therefore a depth of 0 would result in a single page being scanned, while a depth of 5 would result in 6 total pages being scanned.
In order to call additional scanners I am going to need to track a couple of new parameters: a pool of URLs to consider for additional scans and a list of pages I have already scanned. I also need a new function I can call recursively for additional scans from the crawl function.
public static function crawl(string $seedUrl, int $depth): array
{
$webpages = array();
$urlPool = array();
$scannedPages = array();
$seedPage = self::request($seedUrl);
$urlPool = array_merge($urlPool, $seedPage->getInternalUrls());
array_push($scannedPages, $seedPage->getPageUrl());
array_push($webpages, $seedPage->getResult());
self::depthScanning($webpages, $urlPool, $scannedPages, $depth);
return $webpages;
}self::depthScanning function.My depth scanning function needs to keep track of the depth parameter, scan over urlPool looking for a URL that does not exist in scannedPages, and then scan it before starting the process over again until it has completed depth times or run out of pages to scan.
private static function depthScanning(&$webpages, &$urlPool, &$scannedPages, $depth)
{
while ($depth > 0) {
$urls = count($urlPool);
for ($i = 0; $i < $urls; $i++) {
if (in_array($urlPool[$i], $scannedPages) || $urlPool[$i][0] === "#") {
continue;
} else {
$page = self::request($urlPool[$i]);
$urlPool = array_merge($urlPool, $page->getInternalUrls());
array_push($webpages, $page->getResult());
array_push($scannedPages, $page->getPageUrl());
self::depthScanning($webpages, $urlPool, $scannedPages, --$depth);
break 2;
}
}
// Ran our of URLs to scan without hitting depth limit
return;
}
return $webpages;
}break 2; is not a statement I get to use very often. Without the 2 I would be scanning every page available for each level of depth, instead of one page per level.To make sure it all works:

With a depth of 3, I scanned 4 different pages. That is a successful recursive scan. Time to finish up and draw a display for a completed result.
Results Display
Now that I have an array of JSON objects from an API call, I can return to my view and start working on incorporating the new data into my display. Since I am loading Bootstrap 5 on the front end, I should be able to utilize the Collapse element to contain the results page nicely. Time to put on my front-end developer hat and get to work.
First off, as with all things Laravel it includes libraries by default I will not need. Removing those means I get a faster build time and a faster load time on the project itself, so it is time to strip those away.
"axios": "^0.25",
"laravel-mix": "^6.0.6",
"lodash": "^4.17.19",
"postcss": "^8.1.14"I am not going to use axios for my request handling, and I am not planning any functionality that depends on lodash. I do not know yet if I will be writing any CSS, so I will leave the postcss bundler in place. I will need laravel-mix for bundling everything up afterwards, leaving me with 2 libraries.
"laravel-mix": "^6.0.6",
"postcss": "^8.1.14"laravel-mix would have removed axios and lodash when bundling via tree-shaking anyways, but now I know it is gone for sure and my building is a bit quicker.Results Sub-view
Since the results display is a self-contained display that could be used elsewhere in the future, it deserves its own view. With Laravel using Blade templates I can easily include the sub-view in my main view and draw things as a single page while keeping my code nice and organized. Inside my main view I includes another view with the following line:
@include('results')
and to start with, the contents of views/results.blade.php:
<div id="result-container-collapse">
<div id="result-container">
</div>
</div>Additionally now that I am working with multiple views, lets get my inline CSS out of search.blade.php and into its own CSS file.
Fun fact, in the 750 libraries that Laravel includes by default sass and sass-loader are not included, despite laravel-mix supporting compiling .scss files. I have to modify webpack.mix.js to tell it I am going to use SASS now:
const mix = require('laravel-mix')
mix.js('resources/js/app.js', 'public/js')
.sass('resources/css/app.scss', 'public/css');/web/webpack.mix.jsAnd now compiling my code with npm run dev will cause the sass and sass-loader packages to be installed. In order to load bootstrap this way, I am also need to install it via npm. Once its installed, I am only going to load the components I need into my new stylesheet (thereby avoiding loading additional code, but also avoiding needing popperjs as a dependency):
@import "node_modules/bootstrap/scss/functions";
@import "node_modules/bootstrap/scss/variables";
@import "node_modules/bootstrap/scss/mixins";
@import "node_modules/bootstrap/scss/root";
@import "node_modules/bootstrap/scss/grid";
@import "node_modules/bootstrap/scss/tables";
@import "node_modules/bootstrap/scss/forms";
@import "node_modules/bootstrap/scss/buttons";
@import "node_modules/bootstrap/scss/spinners";
@import "node_modules/bootstrap/scss/badge";
@import "node_modules/bootstrap/scss/helpers";
html {
height: 100vh;
}
body {
height: 100%;
}
#search-url-depth {
flex: 0 1 100px;
}
@import "node_modules/bootstrap/scss/bootstrap"And I am in business. I am going to skip over some of the front end design and challenges since this is a back end focused question, but if you are looking for more information check out the comments in /web/resources/app.js in the source.
With some front end magic to format the data I am returning from the Webpage class, I now have a crawler that gives me outputs in a nicely formatted display:
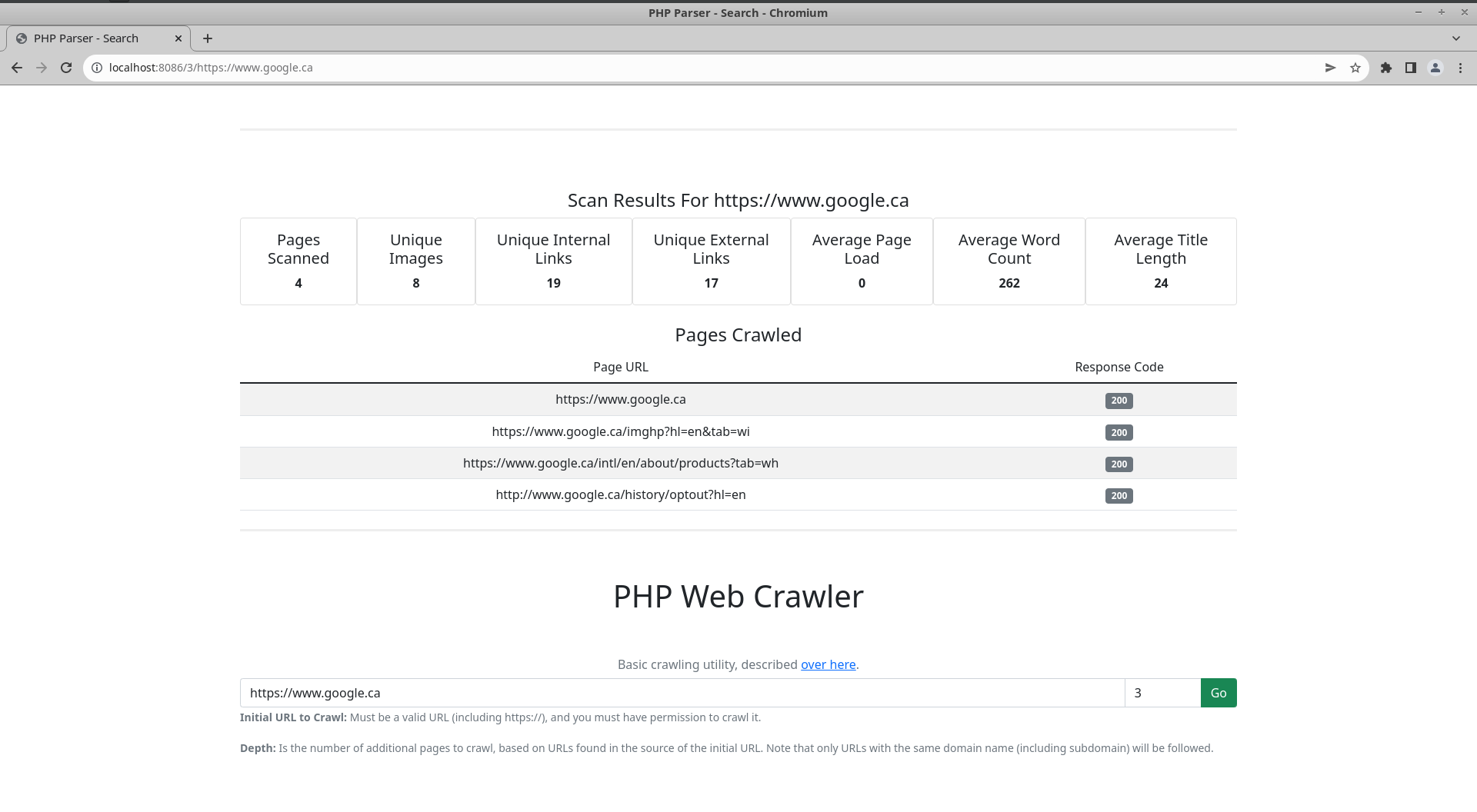
And reviewing all of the original questions, I appear to have met all of the coding requirements.
Additional Bug Fixes
Trailing Slash
In the version above, pages with a trailing slash were treated as different pages than those without. If https://google.ca/ was my seed URL and it contained a link to https://google.ca, both would appear in the results. To work around this problem I now hash the contents of each page and store a collection of hashes I have processed so far. If a hash has already appeared the web crawler moves on to the next page.
Heroku Support
Heroku has two unique twists in their docker environment: they appear to inject modules into a web container's apache configuration, and they require that you read in the port to bind to from the environment.
Apache module injection
This issue caught me by surprise - the following error occurs when you try and launch a container built with the above configuration on Heroku:
Starting process with command `apache2-foreground`
State changed from starting to up
AH00534: apache2: Configuration error: More than one MPM loaded.
Process exited with status 1
State changed from up to crashed
The whole purpose of bundling an application in a docker container is to include all of the libraries and prerequisites as part of the shipped project, so the idea that Heroku is now injecting additional modules that need to be accounted for is a bit of a strange one. Thankfully, before too much research and troubleshooting I stumbled across a Github issue that was related. Specifically, this comment from user @njam:
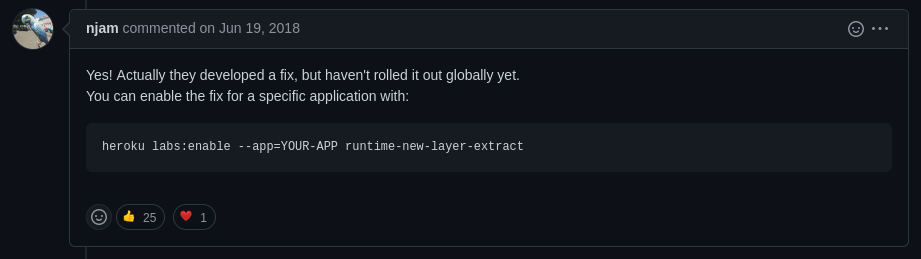
Which does indeed solve the problem. The fact that I had to rely on a Github issue for an unrelated project to Heroku in order to get a docker container to not be modified by the hosting platform is a very interesting concept though. What else could they be editing?
Port Binding
Heroku has also made the peculiar design decision to forego the docker networking functionality entirely, and instead demand that you bind to a specific port available in the environment. Unfortunately this means I now have to make modifications to my docker container specifically to support running it via Heroku.
First, my configuration file 001-crawler.conf needs to change:
<VirtualHost *:80>Becomes:
<VirtualHost *:${PORT}>Then, I need to modify a new file that I was not previously overriding in the container, ports.conf:
LISTEN ${PORT}ports.conf file, it is only 1 line.Next, I need to update my Dockerfile to copy the new file into the container:
FROM php:8-apache
RUN a2enmod rewrite
COPY ./web /var/www/html
COPY ./.env ./web/.env
COPY ./crawler/001-crawler.conf /etc/apache2/sites-available/001-crawler.conf
COPY ./crawler/ports.conf /etc/apache2/ports.conf
RUN chown -R www-data:www-data /var/www/html && a2ensite 001-crawler.conf && a2dissite 000-default.conf.env is not covered above - it contains the Laravel configuration, and it is copied into the root folder to support running the project as an image instead of having to build the code from source.And finally, I need to update my own docker-compose.yml I use locally for developing/testing:
version: "3"
services:
php-crawler:
build: "."
volumes:
- "./web:/var/www/html"
ports:
- "8088:8088"
environment:
- PORT=8088
ports mapping.Source
The entirety of the final source code used here is available over at https://github.com/tharbakim/phpCrawler
Additional Notes/Extensions
There is no Rate Limiter included in this package. In order to use Laravel's rate limiting functionality there has to be a data store available to hold the cached request counts.
Laravel's Http wrapper allows for concurrent requests. I could use it to increase the overall speed of the project - but the parsing/analysis phase would still be single threaded.
A handful of small features would make this a much more exciting project to use, and would all serve for good extensions:
- A toggle to randomize the internal links that are followed after the seed url is analysed
- A true "depth" option to scan all of the links available, going
xlevels down the tree. - The ability to save results, and compare to a previous scan.